Projects old
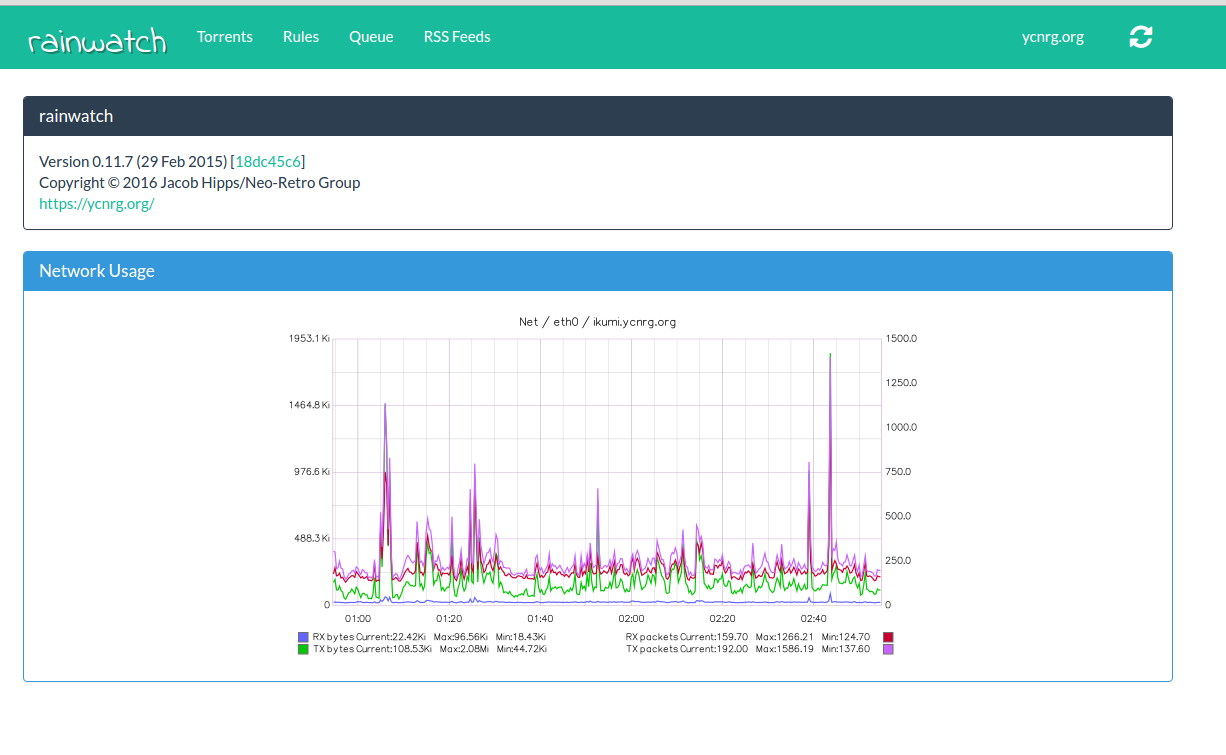
★ rainwatch
rainwatch is a tool for managing downloads from torrent clients. It was originally built with Deluge in mind, but support for rTorrent is being added— additional clients may be possible in the future. rainwatch interfaces with the torrent client via RPC, which allows it to invoke any method exposed by the client.
rainwatch was primarily built to easily manage downloaded files on remote seedbox— that is, act on completed torrents based upon a set of rules defined by the user, move them somewhere defined in the ruleset, then transfer those completed torrent files to another destination. To this end, the Paramiko ssh2 library is used to allow full control over transfers (SFTP), as well as run or trigger commands over SSH on another machine. Outbound file transfers are handled via a queue system that utilizes Redis to keep track of waiting files (eg. from a seedbox to a user's home machine). Once the transfer is complete, the user can be notified via Jabber, utilizing the xmpppy library.
For the frontend, AngularJS is used with Flask serving async requests. Currently, the UI only displays status information and a list of active torrents. However, pages to edit rules and scraper sources (eg. RSS feeds, pages, etc.) will be coming soon.
A side-goal of this project is to create an abstraction layer between the RPC interfaces of popular torrent clients by presenting a unified RESTful API that is intuitive and easy to use. The rainwatch web UI accesses this interface to pull current status information, as well as affect changes the user has made.
rainwatch is still a work-in-progress— support for RSS feeds and parsing links from release posts (eg. from a group's Wordpress site) will be coming soon, along with additional directives that can be implemented in the rulesets.
- Language: Python 2.7, Javascript
- Framework: Flask 0.10.1, Paramiko, AngularJS 1.4, Compass
- Database Backend: MongoDB 3.2, Redis 2.8
JIRA: https://jira.ycnrg.org/projects/YRW/issues/
Git: https://git.ycnrg.org/projects/YRW/repos/rainwatch
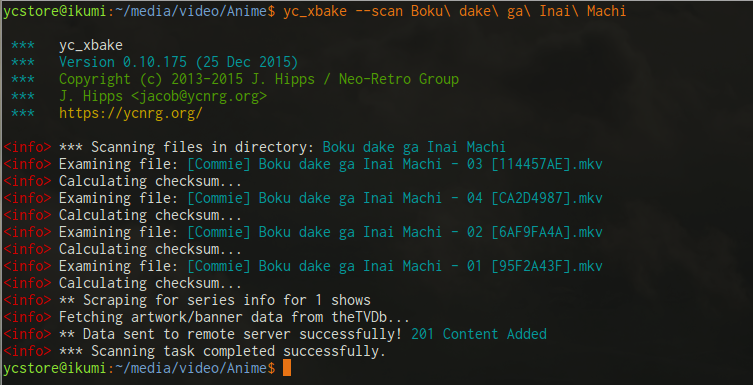
★ XBake
yc_xbake is a multi-purpose tool for managing, cataloging, and transcoding video files, as well as baking subtitles (hardsubbing). It supports running as a daemon, and accepts scan information from authenticated local and remote hosts, as well as managing job queues for file transfer and encoding. Jobs can be submitted to the daemon via the HTTP API, or directly via Redis.
It was originally written in PHP to bake subtitles (hence the name) and transcode video for ycplay.tv, but has since been ported to Python and largely expanded. As this tool was written with ycplay.tv in mind, it is built as a backend service for that site. However, I believe it can also be useful for general-purpose cataloging and transcoding tasks.
XBake supports three primary modes of operation: scan, transcode, and daemon.
In the scan mode, the CLI can be invoked to check a directory (recursively) or a single file. XBake pulls various information from each file, including container and stream data (eg. container info, encoding, bitrates, audio/video/subtitle tracks, etc.), and also calculates a checksum of the file using MD5, ed2k, and CRC32. The scanning module uses various file and path data, as well as metadata, to determine the series name, episode number, season number, etc. An override function is also provided via JSON files (".xbake") or via extended file attributes -- this allows one to give hints to the scanner and scraper for series with ambiguous names (such as House). Once the scan has completed, series metadata is gathered from various sites using one of the scraper modules. Support currently exists for TheTVDB and MAL, but support for additional scrapers is in the works.
Transcode mode takes an input file, then transcodes the file using the given options (or chosen profile) to create an output video with the given bitrate, resolution, and optionally with baked subtitles (hardsubs). This allows transforming a high-bitrate, multi-stream Matroska source file into an MP4 container with an H.264 profile that is fit for streaming via RTMP. The transcoding module can also take a screengrab at a specified offset to use as a video thumbnail. Once the encoding is finished, a 'video' entry in the Mongo database is created automatically, which contains the series metadata that was gathered during the initial scanning process (if the video transcoded exists in the 'files' collection).
Finally, the daemon mode forks off queue runners for automated transcoding and file transfer handling, as well as a Flask-based Web API that can be used to enqueue files for transfer or encoding, and also accepts scan data from a local/remote yc_xbake process.
- Language: Python 2.7
- Framework: Flask 0.10.1 (Web API)
- Database Backend: MongoDB 3.2, Redis 2.8
JIRA: https://jira.ycnrg.org/projects/YXB/issues/
Git: https://git.ycnrg.org/projects/YXB/repos/yc_xbake
★ hotarun.co
hotarun.co is Japanese-language resource website for English-speakers learning Japanese. It utilizes JMDict, KANJIDIC and associated dictionaries from EDRDG as the source for kanji and word information. Other sources include Ulrich Apel's KanjiVG dataset, which is used to create stroke-order diagrams for the kanji card pages, as well as the English-language Wiktionary, which contains excerpts for certain Japanese words.
Tooling was created to parse a variety of data sources to build hotarun.co's Mongo database. Tools are available to parse the EDRDG XML datasets, radical builder, jouyou index, KanjiVG parser/builder, and a corpus parser for gathering statistical usage information. All parsing tools have been collected into edparse2, which is the new all-Python data prep tooling for hotarun.co.
The corpus parser, hotacorp, was used to parse the entire Japanese Wikipedia to establish a baseline for various verb inflections and usage data. This was accomplished by using MeCab to parse each article and output a list of parsed words or tokens, along with various bits of information, such as the base word, inflection, reading, etc. All of this was tallied in a Redis database, then once all ~5GB of text was parsed, a final run was performed to pull the data from the Redis database, and correlate it to the matching words/entries from the JMDict dictionary.
Work on hotarun.co is still in progress. The site is currently functional, and can be used to lookup words and kanji. I would like to improve the 'usage' statistics by parsing other corpus, and possibly even Twitter to gather more informal speech statistics. A quiz feature is also currently in the works, as well as further enhancements to the kanji card and definition pages.
- Language: Javascript (Node.js), Python 2.7
- Framework: Express 4, AngularJS 1.3, Compass 1.0.3
- Database Backend: MongoDB 3.2, Redis 2.8, Neo4j 2.3
- Web Server: Nginx 2.x
Website: https://hotarun.co/
JIRA: https://jira.ycnrg.org/projects/HJP/issues/
Git (frontend): https://git.ycnrg.org/projects/HJP/repos/hotarun-web
Git (tooling): https://git.ycnrg.org/projects/HJP/repos/edparse2
Git (legacy tooling): https://git.ycnrg.org/projects/HJP/repos/edparse